算法入门 算法的世界
算法的定义
在韦氏词典中算法定义为: "在有限步骤内解决数学问题的程序。" 如果运用在计算机领域中,也可以把算法定义为: "为了解决某项工作或某个问题,所需要有限数量的机械性或重复性指令与计算步骤。"
可整除两个整数的最大整数被称为这两个整数的最大公约数,而辗转相除法可以用来求取两个整数的最大公约数,即可以使用这个辗转相除法的算法来求解
辗转相除法
辗转相除法,又名欧几里德算法(Euclidean algorithm),是求最大公约数的一种方法
用较大数除以较小数,再用出现的余数(第一余数)去除除数,再用出现的余数(第二余数)去除第一余数,如此反复,直到最后余数是0为止。如果是求两个数的最大公约数,那么最后的除数就是这两个数的最大公约数
- 大数 ÷ 小数 -> 余数 A
- 小数 ÷ 余数 A -> 余数 B
- 余数 A ÷ 余数 B -> 余数 C
- ·······
- 余数 n ÷ 余数 z = 0
余数 z 为最大公约数
如 100 与 56
| 被除数 | 除数 | 余数 |
|---|---|---|
| 100 | 56 | 44 |
| 56 | 44 | 12 |
| 44 | 12 | 8 |
| 12 | 8 | 4 |
| 8 | 4 | 0 |
4 为 100 与 56 的最大公约数
Golang 实现:
1 | |
算法的条件
| 算法的特征 | 内容与说明 |
|---|---|
| 输入(Input) | 0个或多个输入数据,这些输入必须有清楚的描述或定义 |
| 输出(Output) | 至少会有一个输出结果,不可以没有输出结果 |
| 明确性(Definiteness) | 每一个指令或步骤必须是简洁明确的 |
| 有限性(Finiteness) | 在有限步骤后一定会结束,不会产生无限循环 |
| 有效性(Effectiveness) | 步骤清楚且可行,能让用户用纸笔计算而求出答案 |
时间复杂度
因此用一种 “估算” 的方法来衡量程序或算法的运行时间反而更加恰当,这种估算的时间就是 “时间复杂度” 详细定义如下:
在一个完全理想状态下的计算机中,定义 T(n) 来表示程序执行所要花费的时间,其中 n 代表数据输入量。当然程序的运行时间 (Worse Case Executing Time) 或最大运行时间是时间复杂度的衡量标准,一般以 Big-oh 表示
在分析算法的时间复杂度时,往往用函数来表示它的成长率 (Rate of Growth),其实时间复杂度是一种 “渐进表示法” (Asymptotic Notation)
O(f(n)) 可视为某算法在计算中所需运行时间不会超过某一常数倍数的 f(n),也就是说某算法运行时间 T(n) 的时间复杂度 (time complexity) 为 O(f(n))
意思是存在两个常数 c 与 ,当 n ≥ 时, T(n) ≤ cf(n)。 f(n) 又被称为运行时间的成长率(rate of growth)。由于采用的是宁可高估也不要低估的原则,因此估计出来的函数是真正所需运行时间的上限
运行时间 ,时间复杂度是多少 ?
首先找出常数 c 与 ,当 、c = 10时,若n ≥ ,则 ,因此得知时间复杂度为
事实上,时间复杂度只是执行次数的一个概略的估算,并非真实的执行次数。而 Big-oh 是一种用来表示最坏运行时间的估算方式,也是最常用于描述时间复杂度的渐进式表示法,常见的 Big-oh 下所示
常见的 Big-oh:
| Big-oh | 特色与说明 |
|---|---|
| O(1) | 称为常数时间 (constant time),表示算法的运行时间是一个常数倍数 |
| O(n) | 称为线性时间 (linear time),表示执行的时间会随着数据集合的大小而线性增长 |
| O() | 称为次线性时间 (sub-linear time),成长速度比线性时间还慢,而比常数时间快 |
| O() | 称为平方时间 (quadratic time),算法的运行时间会成为二次方的增长 |
| O() | 称为立方时间 (cubic time),算法的运行时间会成三次方的增长 |
| () | 称为指数时间 (exponential time),算法的运行时间会成 2 的 n 次方增长。例如,解决 Nonpolynomial Problem 问题算法的时间复杂度即为 O() |
| O() | 称为线性乘对数时间,介于线性和二次方增长的中间模式 |
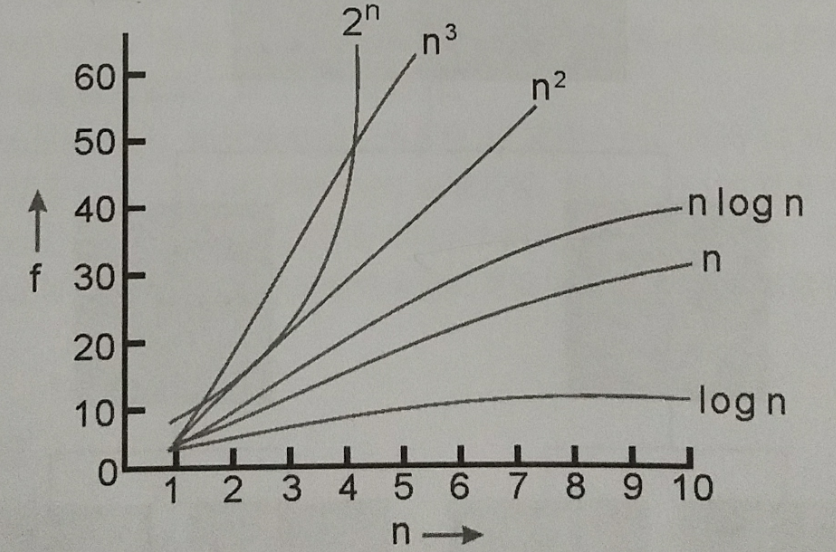
对于 n ≥ 16 时,时间复杂度的优劣比较关系如下:
$ O(1) < O(log_2n) < O(n) < O(nlog_2n) < O(n^2) < O(n^3) < O(2^n) $
应该可能避免使用指数阶的算法
常见的算法
分治法
分治法(Divide and Conquer,也称为”分而治之法”)是一种很重要的算法,可以应用分治法来逐一拆解复杂的问题,核心思想就是一个难以直接决定的大问题依照相同的概念,分割成两个或者更多的子问题,以便各个击破,即”分而治之”。其实,任何一个可以用程序求解的问题所需的计算时间都与其规模有关,问题的规模越小,越容易直接求解。分割问题也是遇到大问题的解决方式,可以使用子问题规模不断缩小,直到这些子问题足够简单到可以解决,最后再将各子问题的解合并得到原问题的最终解答。这个算法应用相当广泛,如快速排序法 (quick sort)、递归算法(recursion)、大整数除法
递归法
递归是一种很特殊的算法,分治法和递归法很像一对孪生兄弟,都是将一个复杂的算法问题进行分解,让规模越来越小,最终使子问题容易求解。递归在早期人工智能所用的语言中,如Lisp、Prolog几乎是整个语言的运行核心,现在许多程序设计语言,包括C、C++、Java、Python等,都具备递归功能。简单来说,对程序设计人员而言,”函数”不单纯只是能够被其他函数调用(或引用)的程序单元,在某些程序设计语言中还提供了自己调用自己的功能,这种调用功能就是所谓的”递归”
从程序设计语言的角度来说,递归的正式定义为:一个函数或子程序,是由自身所定义或调用的,就称为递归(Recursion)。递归至少要满足2个条件:一个可以反复执行的递归过程;一个可以离开递归执行过程的出口
“尾归递归” (Tail Recursion) 就是函数或子程序的最后一条语句为递归调用,因为每次调用后,再回到前一次调用的第一条语句,就是 return 语句,所以不需要再进行任何运算工作
阶乘函数是数学上很有名的函数,对递归法而言,也可以看成是很典型的范例,一般用符号”!”来代表阶乘,如4阶乘可写为4!, n!则表示:
n!= nx(n-1)(n-2)……1
逐步分解它运算的过程,以观察它的规律性:
1 | |
Go 语言的 n! 递归函数算法可以写成如下:
1 | |
在系统具体实现递归时,则要用到堆栈的数据结构。所谓堆栈 (Stack),就是一组相同数据类型的集合,所有的操作均在这个结构的顶端进行,具有”后进后出” (Last In First Out, LIFO)的特性。
著名的斐波那契数列 (Fibonacci Polynomial) 的求解,首先看看斐波那契数列的基本定义:
简单的来说,这个数列的第0项是0、第1项是1,之后的各项的值是由其前面两项的值相加的结果(后面的每项值都是其前两项值之和)。根据斐波那契数列的定义,可以尝试把它设计转为递归形式
1 | |
贪心法
贪心法(Greed Method)又称为贪婪算法,方法是从某一起点开始,在每一个解决问题步骤中使用贪心原则,即采取在当前状态下最有利或最优化的选择,不断地改进该解答,持续在每一步骤中选择最佳的办法,并且逐步逼近给定的目标,当达到某一步骤不能再继续前进时,算法就停止,就是尽可能快地求得更好的解
贪心法的思想虽然是把求解的问题分成若干个子问题,不过不能保证求得的最后解是最佳的。贪心法容易过早做决定,只能求满足某些约束条件下可行解的范围,当然,对于有些问题却可以得到最佳解。贪心法经常用于找出图中的最小生成树(MST)、最短路径与哈夫曼编码等
假设今天去便利店买了几听可乐,要价24元,付给售货员100元,且希望找的钱不要太多硬币,即硬币的总数数量最少,该如何找钱呢?假如目前的硬币有50元,10元,5元,1元四种,从贪心法的策略来说,应找的钱总数是76元,所以一开始选择50元的硬币一枚,接下来就是10元的硬币两枚,最后是5元的硬币和1元的硬币各一枚,总共四枚硬币,这个结果也确实是最佳的解答。
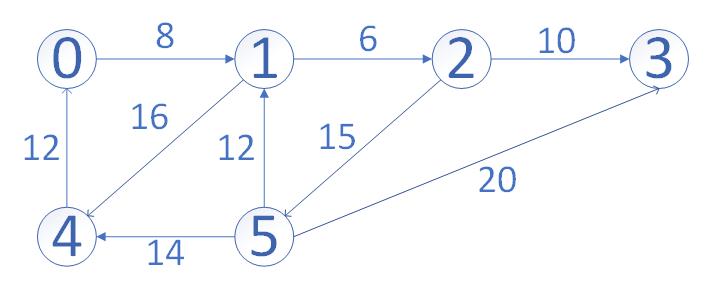
贪心法也很适合用于旅游某些景点的判断,假如要从顶点5走到顶点3,最短的路径该怎么走才好呢?以贪心法来说,当然是先从顶点1最近,接着选择走到顶点2,最后从顶点2走到顶点5,这样的距离是28,可是从中发现从顶点5走到顶点3才是最短的距离,也就是这种情况下,是没办法以贪心法规则来找到最佳的解答
动态规划法
动态规划法 (Dynamic Programming Algorithm,DPA)类似于分治法,在20世纪50年代初由美国数学家 R.E. Bellman 所发明,用于研究多阶段决策过程的优化过程与求得一个问题的最佳解。动态规划法主要的做法是:如果一个问题答案与子问题相关的话,就能将大问题拆解成各个小问题,其中与分治法最大不同的地方是可以让每一个子问题的答案被储存起来,以供下次求解时直接取用。这样的做法不但能减少再次计算的时间,并可将这些解组合成大问题的解答,故而使用动态规划可以解决重复计算的问题
例如前面的斐波那契数列是用类似分治法的递归法,如果改用动态规划法,那么已计算过的数据就不必重复计算了,也不会再往下递归,因而实现了提高性能的目的,例如,想求斐波那契数列的第 4 项数 Fib(4),它的递归过程可以用下图表示
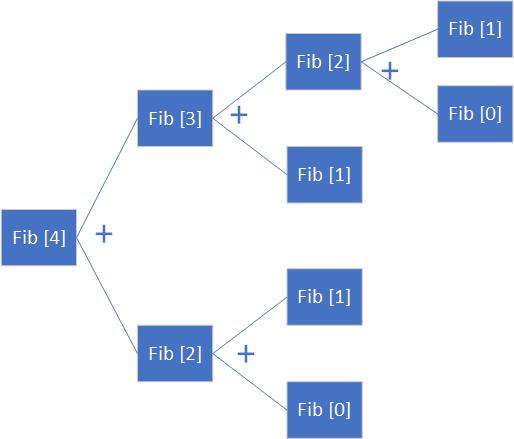
从上面的执行路径图中可以得知递归调用了9次,而执行加法运算4次,Fib(1)与Fib(0)共执行了3次,重复计算影响了执行性能,根据动态规划的思想,可以将算法修改如下:
1 | |
迭代法
迭代法 (iterative method) 是指无法使用公式一次求解,而需要使用迭代,例如用循环去重复执行程序代码的某些部分来得到答案
使用循环来设计一个计算 1!~n! 阶乘的递归程序
1 | |
上述的例子是一种固定执行次数的迭代法,当遇到一个,无法一次以公式求解,又不能确定要执行多少次时,就可以使用 while 循环
while 循环必须加入控制变量的起始值以及递增或递减的表达式,编写循环过程时必须检查离开循环体的条件是否存在,如果条件不存在,就会让循环体一直执行而无法停止,导致”无限循环”,循环结构体通常需要具备三个条件:
- 变量初始值
- 循环条件辨别式
- 调整变量增减值
例如下面的程序:
1 | |
当 i 小于 10 时会执行 while 循环体内的语句,所以 i 会加1,直到i等于10,条件辨别式为 False 时,就会跳离循环了
枚举法
枚举法又称为穷举法,枚举法是一种常见的数学方法,是在日常中用到最多的一种算法,它的核心思想就是列举所有的可能。根据问题要求,逐一列举问题的解答,或者为了便于解决问题,把问题分为不重复、不遗漏的有限种情况,逐一列举各种情况,并加以解决,最终达到解决整个问题的目的。枚举法这种分析问题、解决问题的方法,得到的结果总是正确的,枚举算法的缺点就是速度太慢
当某数 1000 依次减去 1,2,3······直到哪一个数时,相减的结果开始为负数,这是很纯粹的枚举法应用,只要按序减去 1,2,3,4,5,6·····
1000-1-2-3-4-5-6... .-? < 0
用 Go 写成的算法如下:
1 | |
简单来说,枚举法的核心概念就是将要分析的项目在不遗漏的情况下逐一列举出来,再从所列举的项目中去找到自己所需要的目标对象
回溯法
“回溯法” (Backtracking) 也算是枚举法中的一种,对于某些问题而言,回溯法是一种可以找出所有(或一部分)解的一般性算法,同时避免枚举不正确的数值。一旦发现不正确的数值,就不再递归到下一层,而是回溯到上一层,以节省时间,是一种走不通就退回再走的方式。它的特点主要是在搜索过程中寻找问题的解,当发现不满足求解条件时,就回溯(返回),尝试别的路径,避免无效搜索
例如,老鼠走迷宫就是一种 “回溯法”